Iteration Node
The Iteration Node is a component for performing repetitive operations on elements within an array until all outputs are complete. This node applies the same logical steps to each list item, facilitating complex processing within workflows.
Scenarios
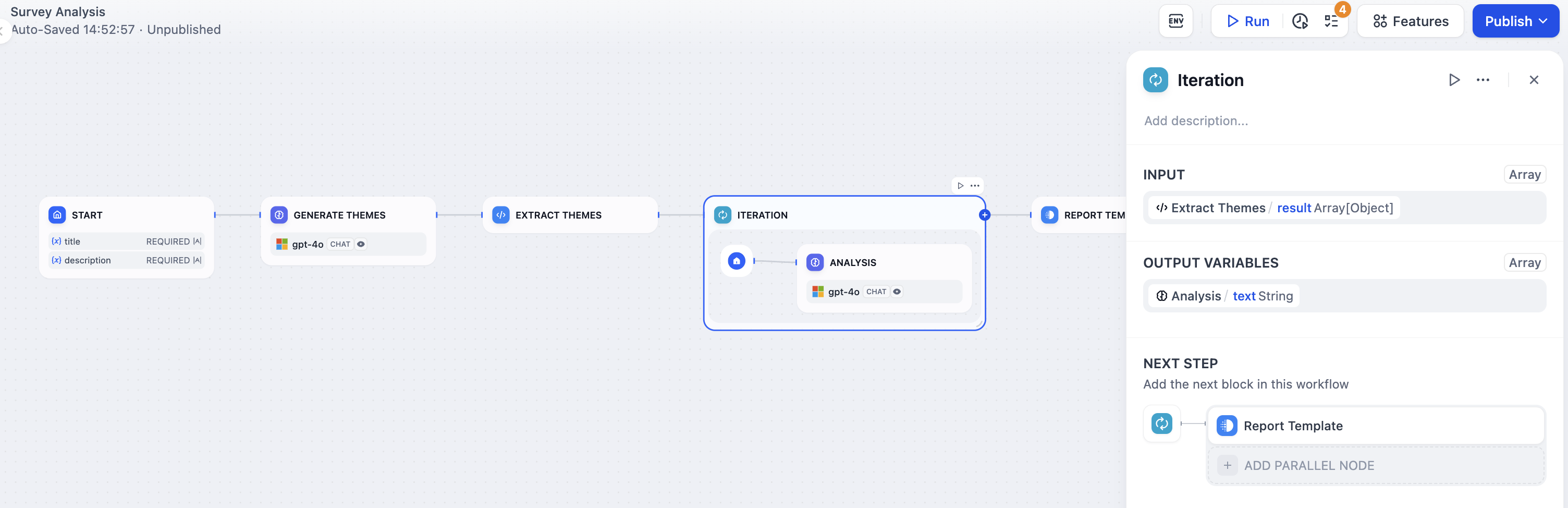
Example: Data-Driven Customer Survey Analysis
-
Initial Setup: Start by inputting survey metadata, such as survey title and description, into the Start Node to establish the foundation.
-
Identify Key Topics: Use an LLM Node to generate major themes and relevant questions from the survey data.
-
Arrange Data Structure: Use a Code Node to convert the survey responses into an array format for easier handling.
-
Iterative Analysis Process: Employ the Iteration Node to wrap around an LLM Node, systematically analyzing responses for each identified theme.
-
Transform Results: Use a Template Node to recompile the analysis results from an array back into a cohesive report.
-
Output Final Report: Finalize the process with an End Node to present a comprehensive survey analysis.
Utilizing Array-Formatted Content:
-
Using the CODE Node: Script logic to derive and structure data into arrays.
-
Using the Parameter Extraction Node: Capture specific data parameters to form arrays efficiently.
Converting Array-Formatted Content to Text:
The Iteration Node's output is array-based and needs conversion to a text format. Apply a conversion step to turn these arrays back into accessible text.
-
Using a Code Node: Craft the conversion of arrays into readable text through programming.
-
Using a Template Node: Customize templates to specify output formats, ensuring the final text is organized and meets desired presentation standards.
Code Node
The Code Execution Node enables the integration of Python and NodeJS scripts within workflows, facilitating a wide range of data transformations. This node streamlines complex workflows, making it ideal for tasks such as arithmetic operations, JSON manipulation, text refinement, and more.
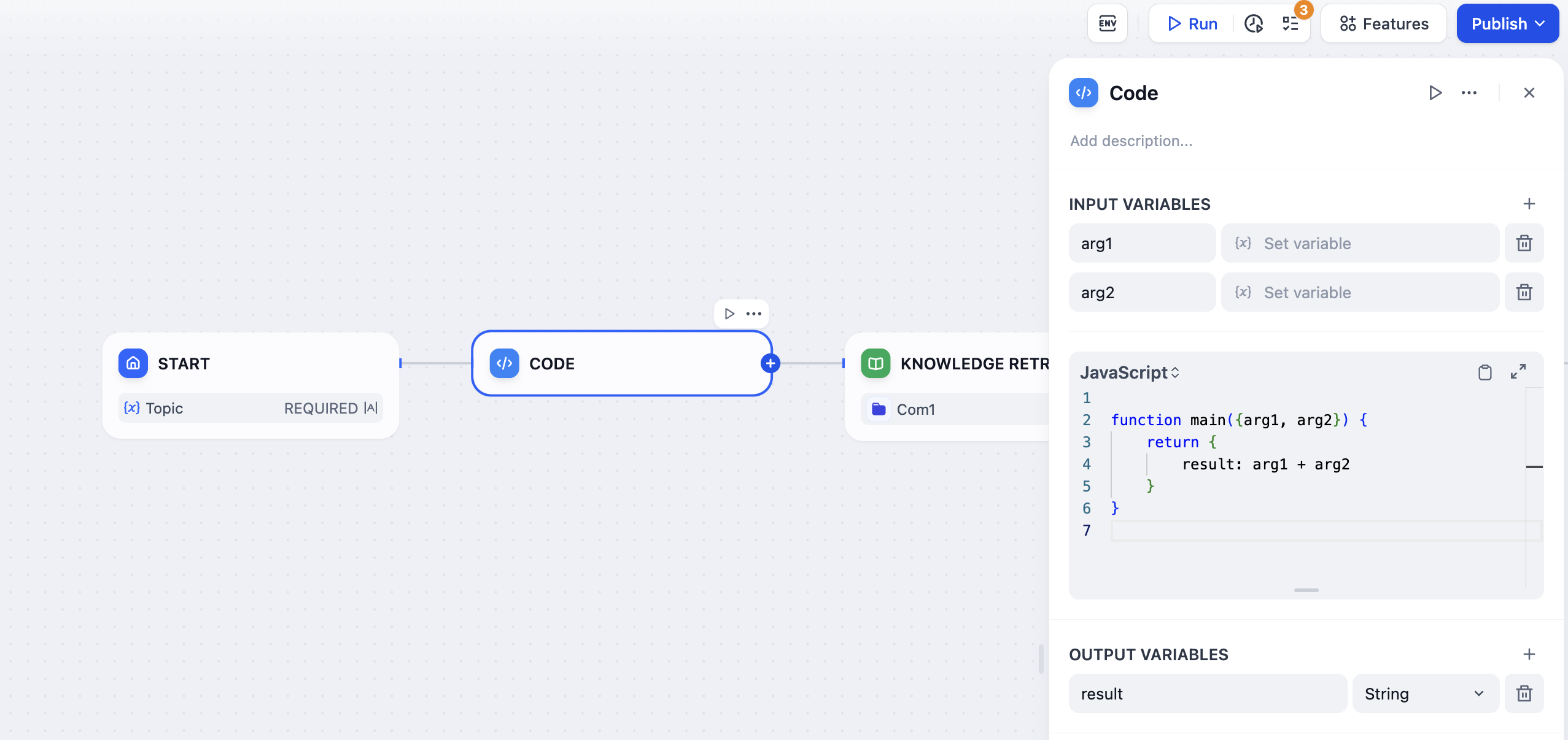
This node provides developers with expanded flexibility, allowing them to incorporate custom Python or JavaScript scripts that enable variable manipulation beyond what standardized nodes offer. By configuring settings, you can define the necessary input and output variables, alongside the corresponding script for execution.
Scenarios
-
Structured Data Processing
Workflows often involve handling unstructured data, which requires parsing, extraction, and transformation of JSON strings. One example is processing data received from an HTTP Request Node, where data might be nested within XML structures or need specific fields extracted. The Code Node efficiently performs these complex operations.
-
Mathematical Calculations
Workflows that require intricate arithmetic operations or statistical analyses greatly benefit from the Code Node. It can handle complex mathematical formulas and provide insights into data through calculated analyses, enhancing decision-making processes.
-
Data Aggregation
The Code Node excels at merging multiple data streams, such as combining the results of knowledge base queries, integrating outcomes from various data searches, or unifying API call data. It seamlessly brings together diverse data sources for comprehensive analysis.
Security Considerations
Both the Python and JavaScript environments used by the Code Node are securely sandboxed, ensuring robust security. This isolation prevents the usage of functions that might heavily tax system resources or introduce security threats. These include actions such as direct file system interactions, making external network requests, or performing operating system-level commands. By enforcing these restrictions, DigiAI ensures code is executed safely while safeguarding system resources.
Template Node
The Template Node is an invaluable tool for dynamically formatting and merging variables from previous nodes into a cohesive text output using Jinja2—an advanced templating engine for Python. This node is particularly effective when you need to amalgamate data from various sources into a specific format that later nodes in the workflow require.
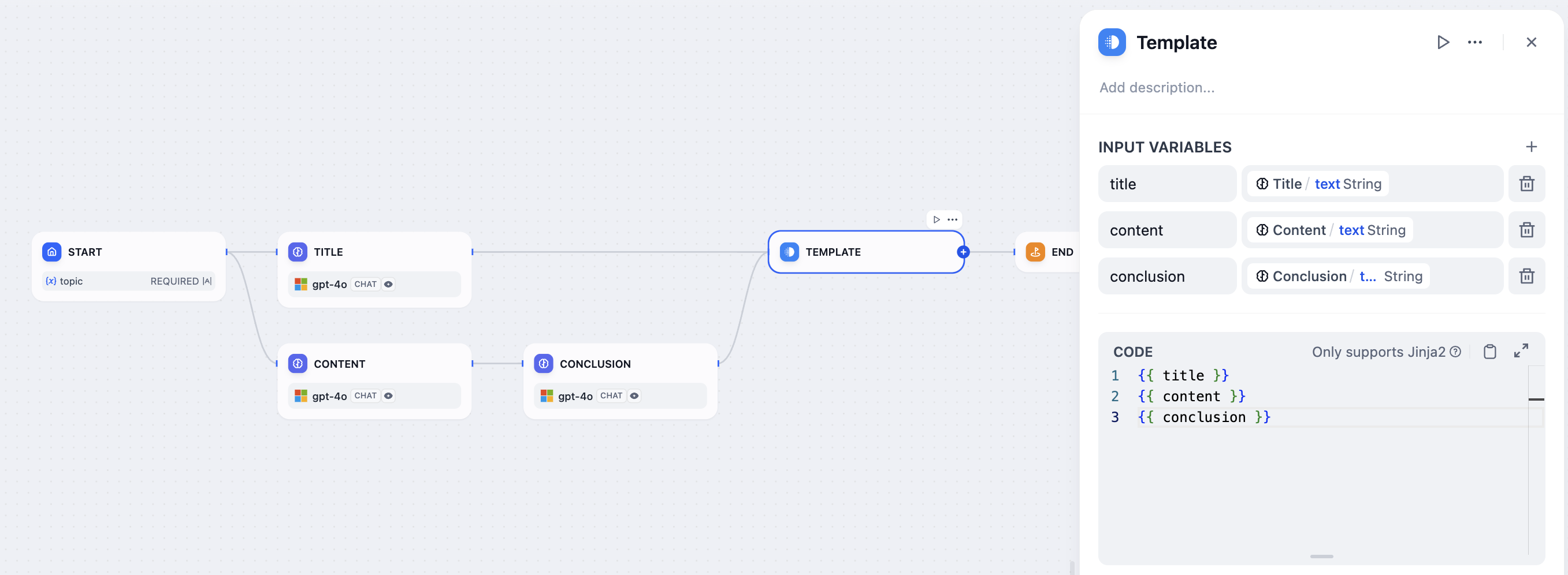
Key Features
-
Dynamic Text Formatting
Utilizing the robust Jinja2 syntax, the Template Node allows the seamless integration of different data variables into a unified text string, providing an organized and consistent format.
-
Data Consolidation from Multiple Inputs
The node excels at synthesizing diverse data points sourced from preceding nodes, arranging them into a structured output. This function is crucial when combining elements like user inputs, API call results, and database queries to prepare them for subsequent processing stages.
-
Preparing Data for Further Processing:
By formatting data into a structured output, the Template Node ensures that subsequent nodes receive the information in an expected arrangement, enhancing the workflow's coherence and reliability. Whether you are preparing detailed reports, structured emails, or formatted datasets, this node simplifies the process.
Variable Aggregator Node
The Variable Aggregator Node is a potent mechanism within workflows that consolidates variables originating from multiple branches into a unified variable. This integration ensures streamlined configurations for downstream processing nodes and enhances data management efficiency.

This node serves as a conduit for combining outputs from various branches, allowing collected results to be accessed through a singular variable regardless of the branch from which they originate. It is particularly advantageous in multi-path scenarios where it assimilates variables performing identical functions across different branches into one cohesive output variable, thereby eliminating the redundancy of redefining these variables in subsequent nodes.
Data Type Compatibility
The Variable Aggregator efficiently handles various data types, including strings, numbers, objects, and arrays. It aggregates variables of the same type; for instance, if the initial variable is a String, subsequent nodes will be limited to adding only String-type variables. This ensures coherence and avoids potential data type conflicts within the aggregation process.
Aggregation Group
Once the aggregation group is enabled, the variable aggregator allows for the combination of multiple variable groups, where each group must consist of variables of the same data type for the aggregation process.
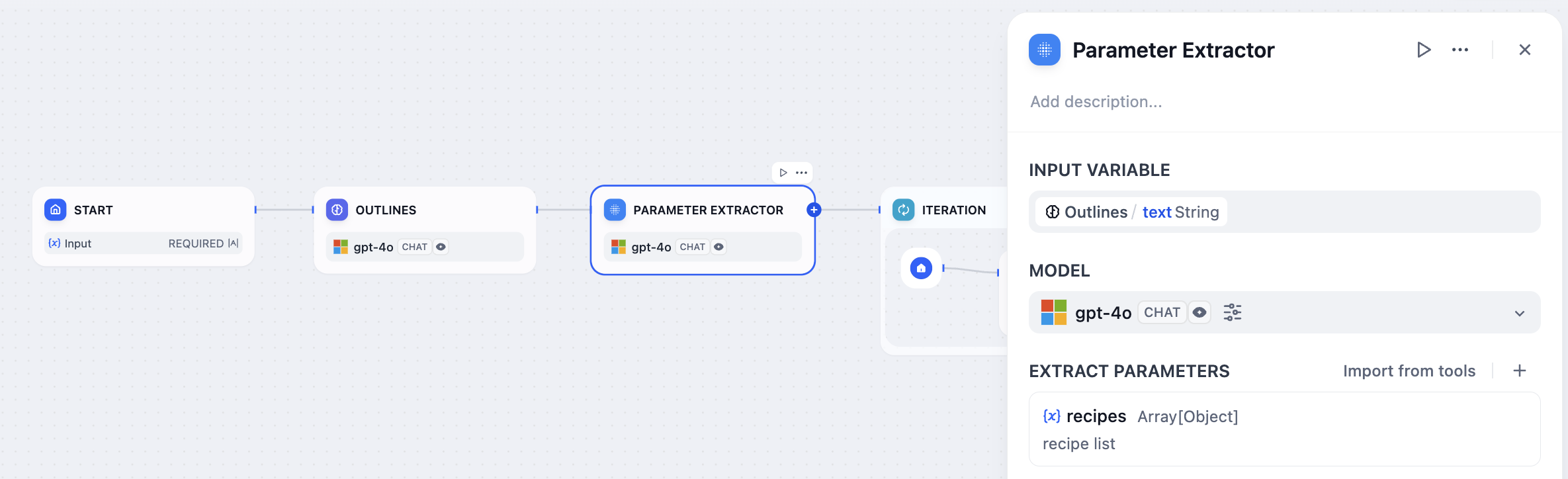
Parameter Extraction Node
The Parameter Extraction Node is a tool that leverages LLM (Large Language Model) capabilities to infer and extract structured parameters from natural language inputs. These structured parameters are essential for invoking tools or configuring HTTP Request Node within workflows.
DigiAI workflows come equipped with an array of tools that require structured input parameters. The Parameter Extraction Node converts the user's natural language inputs into structured formats, ensuring they are compatible with various tools for smooth invocation and operation.
Certain nodes demand specific data formats, such as arrays for the Iteration Node. The Parameter Extraction Node adeptly transforms content into these necessary structures, streamlining subsequent workflow operations.
Scenarios
-
Tool Parameter Extraction from Natural Language
Consider a scenario where you wish to create a weather reporting application. The weather tool needs specific parameters such as location or forecast date. The Parameter Extraction Node processes an input like "What's the weather in New York tomorrow?" and extracts "New York" and "tomorrow" as parameters for precise tool queries.

-
Transforming Text into Structured Data
In an interactive recipe creation application, chapter content can be converted from text to an array format. The node serves as a preliminary step that enables the Iteration Node to handle each recipe step systematically, enhancing multi-round processing.
-
Using Structured Data for External Requests:
Extract parameters to facilitate HTTP Request Node operations, allowing for the retrieval of external data sources, initiation of webhooks, image generation requests, or any scenario requiring structured interaction with external systems.
Configuration Steps
-
Select the Input Variable: Identify the variable input for parameter extraction, which typically comes from user queries or natural language inputs within the workflow.
-
Choose the Model: The effectiveness of parameter extraction relies on the chosen LLM, which uses its inference skills and structured generation capabilities to interpret and convert input data.
-
Define Parameters to Extract: Manually add required parameters or import them swiftly from existing tools to align with workflow needs.
-
Write Instructions: Provide clear instructions and examples to the LLM. Offering illustrative samples can enhance the accuracy and reliability of parameter extraction, especially in scenarios involving complex data.
HTTP Request Node
The HTTP Request Node is designed to facilitate interconnectivity between workflows and external services by sending HTTP protocol-based server requests. It is ideal for tasks that involve retrieving external data, activating webhooks, generating content like images, or downloading various file types, thereby ensuring seamless integration with a multitude of online services.
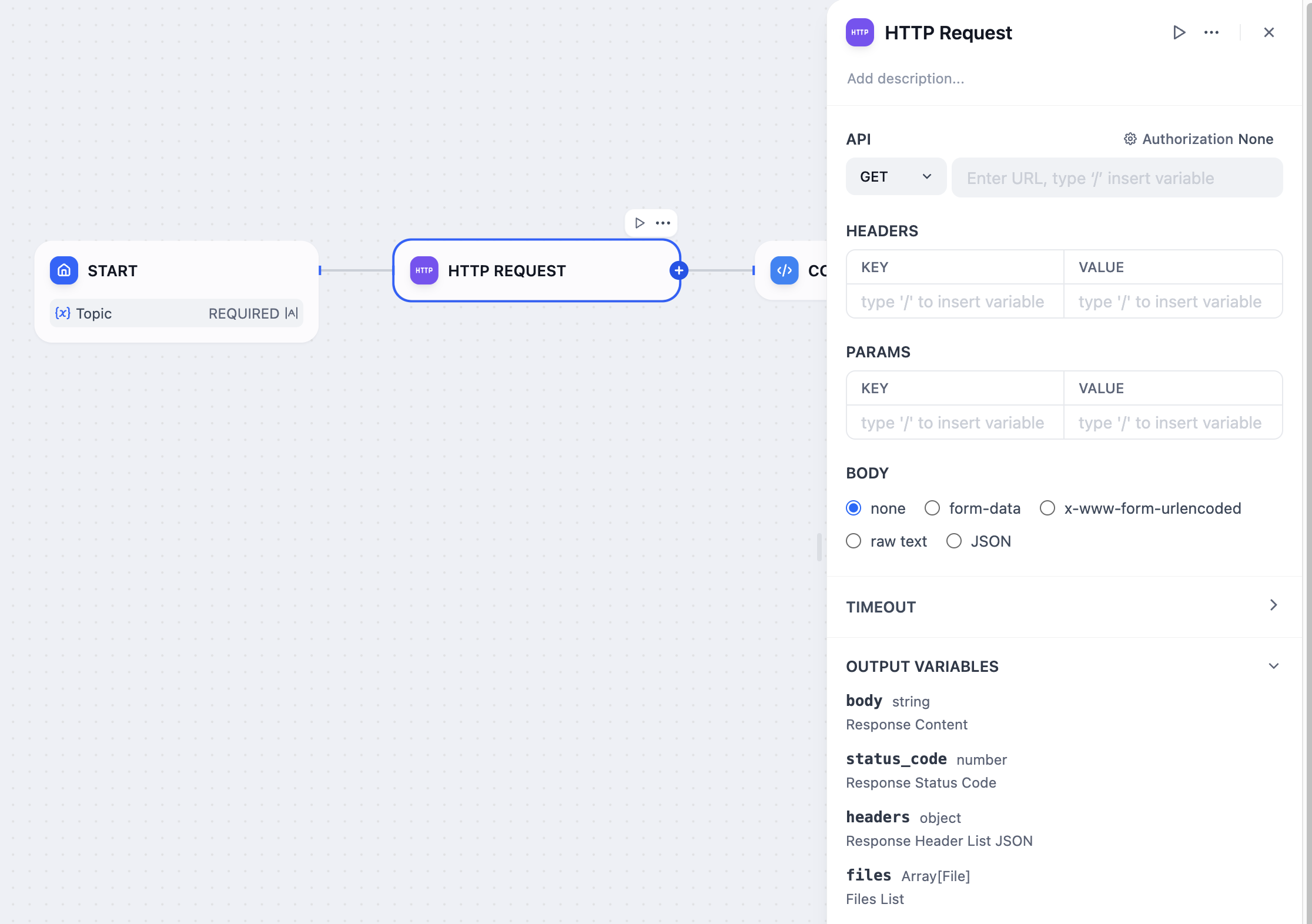
HTTP Request Methods Supported
-
GET: Utilized to retrieve specific resources from a server.
-
POST: Employed for submitting data to a server, often used for form submissions or file uploads.
-
HEAD: Similar to GET, this request fetches the response headers only, without the actual resource body.
-
PATCH: Allows for partial updates to existing resources.
-
PUT: Used to upload or update resources on a server, either creating or modifying existing content.
-
DELETE: Sends a request for the server to remove a specified resource.
Each HTTP request can be extensively configured, allowing you to specify parameters such as URLs, request headers, query parameters, request body details, and necessary authentication credentials.
The data returned from an HTTP request encompasses the response body, status code, headers, and any associated files. Crucially, if the server returns a file (currently supporting image types), the node can save the file automatically for successive workflow actions. This capability not only enhances processing efficiency but also simplifies the workflow’s response handling, particularly when files are involved.